XML ஐ C# இல் படித்தல்
C# இல் XML கோப்பைப் படிக்க பல வழிகள் உள்ளன, மேலும் ஒவ்வொரு முறைக்கும் அதன் நன்மைகள் மற்றும் தீமைகள் உள்ளன, மேலும் தேர்வு திட்டத்தின் தேவைகளைப் பொறுத்தது. C# இல் XML கோப்பைப் படிக்க சில வழிகள் கீழே உள்ளன:
- XmlDocument ஐப் பயன்படுத்துதல்
- XDocument ஐப் பயன்படுத்துதல்
- எக்ஸ்எம்எல் ரீடரைப் பயன்படுத்துதல்
- Xml to LINQ ஐப் பயன்படுத்துதல்
- XPath ஐப் பயன்படுத்துதல்
நான் உருவாக்கிய XML கோப்பின் உள்ளடக்கம் இங்கே உள்ளது மற்றும் வரும் முறைகளில் விளக்கத்திற்காகப் பயன்படுத்தப்படும்:
< ?xml பதிப்பு = '1.0' குறியாக்கம் = 'utf-8' ? >
< ஊழியர்கள் >
< பணியாளர் >
< ஐடி > 1 ஐடி >
< பெயர் > சாம் போஷ் பெயர் >
< துறை > சந்தைப்படுத்தல் துறை >
< சம்பளம் > 50000 சம்பளம் >
பணியாளர் >
< பணியாளர் >
< ஐடி > 2 ஐடி >
< பெயர் > ஜேன் டோ பெயர் >
< துறை > நிதி துறை >
< சம்பளம் > 60000 சம்பளம் >
பணியாளர் >
< பணியாளர் >
< ஐடி > 3 ஐடி >
< பெயர் > ஜேம்ஸ் பெயர் >
< துறை > மனித வளம் துறை >
< சம்பளம் > 70000 சம்பளம் >
பணியாளர் >
ஊழியர்கள் >
1: XmlDocument ஐப் பயன்படுத்துதல்
C# இல் XML கோப்பைப் படிக்க, நீங்கள் XmlDocument வகுப்பு அல்லது XDocument வகுப்பைப் பயன்படுத்தலாம், இவை இரண்டும் System.Xml பெயர்வெளியின் ஒரு பகுதியாகும். XmlDocument வகுப்பு XMLஐப் படிக்க DOM (ஆவண பொருள் மாதிரி) அணுகுமுறையை வழங்குகிறது, அதேசமயம் XDocument வகுப்பு LINQ (மொழி-ஒருங்கிணைந்த வினவல்) அணுகுமுறையை வழங்குகிறது. XML கோப்பைப் படிக்க XmlDocument வகுப்பைப் பயன்படுத்துவதற்கான எடுத்துக்காட்டு இங்கே:
கணினியைப் பயன்படுத்துதல்;
System.Xml ஐப் பயன்படுத்துதல்;
வகுப்பு திட்டம்
{
நிலையான வெற்றிட முதன்மை ( லேசான கயிறு [ ] args )
{
XmlDocument doc = புதிய XmlDocument ( ) ;
ஆவணம்.சுமை ( 'employees.xml' ) ;
XmlNodeList முனைகள் = doc.DocumentElement.SelectNodes ( '/ஊழியர்கள்/பணியாளர்' ) ;
ஒவ்வொரு ( எக்ஸ்எம்எல்நோட் முனை உள்ளே முனைகள் )
{
லேசான கயிறு ஐடி = முனை.SingleNode தேர்ந்தெடுக்கவும் ( 'ஐடி' ) .உள் உரை;
சரத்தின் பெயர் = முனை.SingleNode தேர்ந்தெடுக்கவும் ( 'பெயர்' ) .உள் உரை;
சரம் துறை = முனை.SingleNode தேர்ந்தெடுக்கவும் ( 'துறை' ) .உள் உரை;
சரம் சம்பளம் = முனை.SingleNode தேர்ந்தெடுக்கவும் ( 'சம்பளம்' ) .உள் உரை;
கன்சோல்.WriteLine ( 'ஐடி: {0}, பெயர்: {1}, துறை: {2}, சம்பளம்: {3}' , ஐடி , பெயர், துறை, சம்பளம் ) ;
}
}
}
இந்தக் குறியீடு XML கோப்பை ஏற்றுவதற்கு XmlDocument வகுப்பையும், பணியாளர் முனைகளின் பட்டியலை மீட்டெடுக்க SelectNodes முறையையும் பயன்படுத்துகிறது. பின்னர், ஒவ்வொரு பணியாளர் முனைக்கும், இது SelectSingleNode முறையைப் பயன்படுத்தி ஐடி, பெயர், துறை மற்றும் சம்பளம் குழந்தை முனைகளின் மதிப்புகளை மீட்டெடுக்கிறது மற்றும் Console.WriteLine ஐப் பயன்படுத்தி அவற்றைக் காண்பிக்கும்:

2: XDocument ஐப் பயன்படுத்துதல்
மாற்றாக, LINQ அணுகுமுறையைப் பயன்படுத்தி XML கோப்பைப் படிக்க XDocument வகுப்பையும் நீங்கள் பயன்படுத்தலாம், மேலும் அதை எப்படிச் செய்வது என்பதை விளக்கும் குறியீடு கீழே உள்ளது:
கணினியைப் பயன்படுத்துதல்;வகுப்பு திட்டம்
{
நிலையான வெற்றிட முதன்மை ( லேசான கயிறு [ ] args )
{
XDocument doc = XDocument.Load ( 'employees.xml' ) ;
ஒவ்வொரு ( XElement உறுப்பு உள்ளே doc.சந்ததியினர் ( 'பணியாளர்' ) )
{
முழு எண்ணாக ஐடி = int.Parse ( உறுப்பு.உறுப்பு ( 'ஐடி' ) .மதிப்பு ) ;
சரம் பெயர் = உறுப்பு. உறுப்பு ( 'பெயர்' ) .மதிப்பு;
சரம் துறை = உறுப்பு.உறுப்பு ( 'துறை' ) .மதிப்பு;
int சம்பளம் = int.Parse ( உறுப்பு.உறுப்பு ( 'சம்பளம்' ) .மதிப்பு ) ;
கன்சோல்.WriteLine ( $ 'ID: {id}, பெயர்: {name}, துறை: {department}, சம்பளம்: {salary}' ) ;
}
}
}
XDocument.Load முறையைப் பயன்படுத்தி XML கோப்பு XDocument பொருளில் ஏற்றப்படுகிறது. XML கோப்பின் 'பணியாளர்' கூறுகள் அனைத்தும் சந்ததியினர் நுட்பத்தைப் பயன்படுத்தி மீட்டெடுக்கப்படுகின்றன. ஒவ்வொரு உறுப்புக்கும், அதன் குழந்தை உறுப்புகள் உறுப்பு முறையைப் பயன்படுத்தி அணுகப்படுகின்றன, மேலும் அவற்றின் மதிப்புகள் மதிப்பு சொத்தைப் பயன்படுத்தி பிரித்தெடுக்கப்படுகின்றன. இறுதியாக, பிரித்தெடுக்கப்பட்ட தரவு கன்சோலில் அச்சிடப்படுகிறது.
XDocument System.Xml.Linq நேம்ஸ்பேஸுக்கு சொந்தமானது என்பதை நினைவில் கொள்ளவும், எனவே உங்கள் C# கோப்பின் மேற்புறத்தில் பின்வரும் அறிக்கையைப் பயன்படுத்தி நீங்கள் சேர்க்க வேண்டும்

3: எக்ஸ்எம்எல் ரீடரைப் பயன்படுத்துதல்
XmlReader என்பது XML கோப்பை C# இல் படிக்க விரைவான மற்றும் திறமையான வழியாகும். இது கோப்பை தொடர்ச்சியாகப் படிக்கிறது, அதாவது ஒரு நேரத்தில் ஒரு முனையை மட்டுமே ஏற்றுகிறது, இல்லையெனில் நினைவகத்தில் கையாள கடினமாக இருக்கும் பெரிய XML கோப்புகளுடன் வேலை செய்வதற்கு இது சிறந்தது.
கணினியைப் பயன்படுத்துதல்;System.Xml ஐப் பயன்படுத்துதல்;
வகுப்பு திட்டம்
{
நிலையான வெற்றிட முதன்மை ( லேசான கயிறு [ ] args )
{
பயன்படுத்தி ( XmlReader reader = XmlReader.Create ( 'employees.xml' ) )
{
போது ( வாசகர்.படிக்க ( ) )
{
என்றால் ( reader.NodeType == XmlNodeType.Element && வாசகர்.பெயர் == 'பணியாளர்' )
{
கன்சோல்.WriteLine ( 'ஐடி:' + reader.GetAttribute ( 'ஐடி' ) ) ;
வாசகர்.ReadToDescendant ( 'பெயர்' ) ;
கன்சோல்.WriteLine ( 'பெயர்:' + reader.ReadElementContentAsString ( ) ) ;
வாசகர்.ReadToNextSibling ( 'துறை' ) ;
கன்சோல்.WriteLine ( 'துறை: ' + reader.ReadElementContentAsString ( ) ) ;
வாசகர்.ReadToNextSibling ( 'சம்பளம்' ) ;
கன்சோல்.WriteLine ( 'சம்பளம்:' + reader.ReadElementContentAsString ( ) ) ;
}
}
}
}
}
இந்த எடுத்துக்காட்டில், நாங்கள் XmlReader ஐப் பயன்படுத்துகிறோம். XmlReader இன் நிகழ்வை உருவாக்க ஒரு முறையை உருவாக்கவும் மற்றும் XML கோப்பு பாதையை ஒரு அளவுருவாக அனுப்பவும். எக்ஸ்எம்எல் ரீடரின் ரீட் முறையைப் பயன்படுத்தி எக்ஸ்எம்எல் பைல் நோட் மூலம் நோட் மூலம் படிக்க சிறிது நேர வளையத்தைப் பயன்படுத்துகிறோம்.
லூப்பின் உள்ளே, XmlReader இன் NodeType மற்றும் Name பண்புகளைப் பயன்படுத்தி தற்போதைய முனை ஒரு பணியாளர் உறுப்புதானா என்பதை முதலில் சரிபார்க்கிறோம். அப்படியானால், ஐடி பண்புக்கூறின் மதிப்பை மீட்டெடுக்க GetAttribute முறையைப் பயன்படுத்துகிறோம்.
அடுத்து, பணியாளர் உறுப்புக்குள் உள்ள பெயர் உறுப்புக்கு ரீடரை நகர்த்த ReadToDescendant முறையைப் பயன்படுத்துகிறோம். பெயர் உறுப்பு மதிப்பு பின்னர் ReadElementContentAsString செயல்பாட்டைப் பயன்படுத்தி பெறப்படுகிறது.
இதேபோல், வாசகரை அடுத்த உடன்பிறப்பு உறுப்புக்கு நகர்த்தவும், துறை மற்றும் சம்பள கூறுகளின் மதிப்பைப் பெறவும் ReadToNextSibling முறையைப் பயன்படுத்துகிறோம்.
இறுதியாக, XML கோப்பைப் படித்து முடித்த பிறகு XmlReader பொருள் சரியாக அகற்றப்படுவதை உறுதிசெய்ய பிளாக்கைப் பயன்படுத்துகிறோம்:
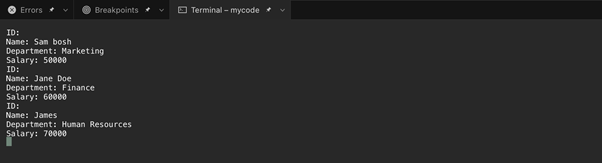
4: XML to LINQ
XML தரவை அணுகுவதற்கும் கையாளுவதற்கும் C# இல் LINQ முதல் XML வரை XML கோப்பைப் படிப்பது ஒரு சக்திவாய்ந்த வழியாகும். LINQ to XML என்பது LINQ தொழில்நுட்பத்தின் ஒரு அங்கமாகும், இது XML தரவுகளுடன் பணிபுரிய எளிய மற்றும் திறமையான API ஐ வழங்குகிறது.
கணினியைப் பயன்படுத்துதல்;System.Linq ஐப் பயன்படுத்துதல்;
System.Xml.Linq ஐப் பயன்படுத்துதல்;
வகுப்பு திட்டம்
{
நிலையான வெற்றிட முதன்மை ( லேசான கயிறு [ ] args )
{
XDocument doc = XDocument.Load ( 'employees.xml' ) ;
var ஊழியர்கள் = இலிருந்து உள்ளே doc.சந்ததியினர் ( 'பணியாளர்' )
தேர்ந்தெடுக்கவும் புதிய
{
ஐடி = இ. உறுப்பு ( 'ஐடி' ) .மதிப்பு,
பெயர் = இ.உறுப்பு ( 'பெயர்' ) .மதிப்பு,
திணை = இ.உறுப்பு ( 'துறை' ) .மதிப்பு,
சம்பளம் = e.Element ( 'சம்பளம்' ) .மதிப்பு
} ;
ஒவ்வொரு ( var பணியாளர் உள்ளே ஊழியர்கள் )
{
கன்சோல்.WriteLine ( $ 'ஐடி: {employee.Id}, பெயர்: {employee.Name}, துறை: {employee.Department}, சம்பளம்: {employee.Salary}' ) ;
}
}
}
இந்தக் குறியீட்டில், முதலில் XDocument.Load() முறையைப் பயன்படுத்தி XML கோப்பை ஏற்றுவோம். பின்னர், XML தரவை வினவுவதற்கு LINQ முதல் XML ஐப் பயன்படுத்துகிறோம் மற்றும் ஒவ்வொரு பணியாளர் உறுப்புக்கான ஐடி, பெயர், துறை மற்றும் சம்பள கூறுகளைத் தேர்ந்தெடுக்கிறோம். இந்தத் தரவை ஒரு அநாமதேய வகையில் சேமித்து, பின்னர் பணியாளரின் தகவலை கன்சோலில் அச்சிட முடிவுகளைச் சுழற்றுவோம்.

5: XPath ஐப் பயன்படுத்துதல்
XPath என்பது ஒரு வினவல் மொழியாகும், இது ஒரு XML ஆவணத்தின் மூலம் குறிப்பிட்ட உறுப்புகள், பண்புக்கூறுகள் மற்றும் முனைகளைக் கண்டறியப் பயன்படுகிறது. XML ஆவணத்தில் தகவல்களைத் தேடுவதற்கும் வடிகட்டுவதற்கும் இது ஒரு பயனுள்ள கருவியாகும். C# இல், XML கோப்புகளிலிருந்து தரவைப் படிக்கவும் பிரித்தெடுக்கவும் XPath மொழியைப் பயன்படுத்தலாம்.
கணினியைப் பயன்படுத்துதல்;System.Xml.XPath ஐப் பயன்படுத்துதல்;
System.Xml ஐப் பயன்படுத்துதல்;
வகுப்பு திட்டம்
{
நிலையான வெற்றிட முதன்மை ( லேசான கயிறு [ ] args )
{
XmlDocument doc = புதிய XmlDocument ( ) ;
ஆவணம்.சுமை ( 'employees.xml' ) ;
// ஆவணத்திலிருந்து ஒரு XPathNavigator ஐ உருவாக்கவும்
XPathNavigator nav = doc.CreateNavigator ( ) ;
// XPath வெளிப்பாட்டைத் தொகுக்கவும்
XPathExpression exr = nav.தொகுத்தல் ( '/ஊழியர்கள்/பணியாளர்/பெயர்' ) ;
// வெளிப்பாட்டை மதிப்பிடவும் மற்றும் முடிவுகளின் மூலம் மீண்டும் செய்யவும்
XPathNodeIterator iterator = nav.Select ( exr ) ;
போது ( மறு செய்கை.MoveNext ( ) )
{
கன்சோல்.WriteLine ( மறு செய்கை.நடப்பு.மதிப்பு ) ;
}
}
}
இந்தக் குறியீடு XmlDocument ஐப் பயன்படுத்தி “employees.xml” கோப்பை ஏற்றுகிறது, ஆவணத்திலிருந்து ஒரு XPathNavigator ஐ உருவாக்குகிறது, மேலும்

குறிப்பு: எக்ஸ்எம்எல் ஆவணத்திலிருந்து கூறுகள் மற்றும் பண்புக்கூறுகளைத் தேர்ந்தெடுக்க XPathஐப் பயன்படுத்துவது சக்திவாய்ந்த மற்றும் நெகிழ்வான வழியாகும், ஆனால் நாம் விவாதித்த மற்ற சில முறைகளைக் காட்டிலும் இது மிகவும் சிக்கலானதாக இருக்கும்.
முடிவுரை
XmlDocument வகுப்பைப் பயன்படுத்துவது முழு DOM கையாளுதல் திறன்களை வழங்குகிறது, ஆனால் இது மற்ற முறைகளைக் காட்டிலும் மெதுவாகவும் அதிக நினைவாற்றல் கொண்டதாகவும் இருக்கும். எக்ஸ்எம்எல் ரீடர் கிளாஸ் பெரிய எக்ஸ்எம்எல் கோப்புகளைப் படிப்பதற்கு ஒரு சிறந்த தேர்வாகும், ஏனெனில் இது வேகமான, முன்னோக்கி மட்டுமே மற்றும் தற்காலிக சேமிப்பு அல்லாத ஸ்ட்ரீம் அடிப்படையிலான அணுகுமுறையை வழங்குகிறது. XDocument வகுப்பு ஒரு எளிமையான மற்றும் சுருக்கமான தொடரியல் வழங்குகிறது, ஆனால் இது XmlReader போல செயல்திறன் கொண்டதாக இருக்காது. கூடுதலாக, LINQ to XML மற்றும் XPath முறைகள் XML கோப்பிலிருந்து குறிப்பிட்ட தரவைப் பிரித்தெடுக்க சக்திவாய்ந்த வினவல் திறன்களை வழங்குகின்றன.